Come cambierà il nostro modo di fare le ricerche con il Grafo della Conoscenza di Google?
Quante volte ci è capitato di cercare una cosa e ricevere un’elenco di risultati che parlano di tutt’altro? Naturalmente una parola può avere più significati, e se la estrapoliamo dal contesto può essere difficile comprenderne il significato reale.
“Per un motore di ricerca i termini “taj mahal“, ad esempio, sono state sempre due semplici parole”
Lo dice Amit Singhal, ovvero colui che ha scritto l’algoritmo di ricerca di Google. Con l’importanza che il “web semantico” sta acquisendo, ovvero l’associazione tra le pagine web e le informazioni in esse contenute, il progetto Google Knowledge Search da ulteriore spinta ad un processo di trasformazione del web. L’obiettivo di big-G è chiaro: catalogare le pagine web, cercando di capire gli argomenti di cui parlano, e quindi aumentare la precisione e la rilevanza dei suoi risultati di ricerca.
“Non sarebbe meraviglioso se google potesse capire le parole che scrivi quando fai una ricerca? Perché non sono solo parole, ma sono cose reali, e si riferiscono a persone reali, fatti reali.”
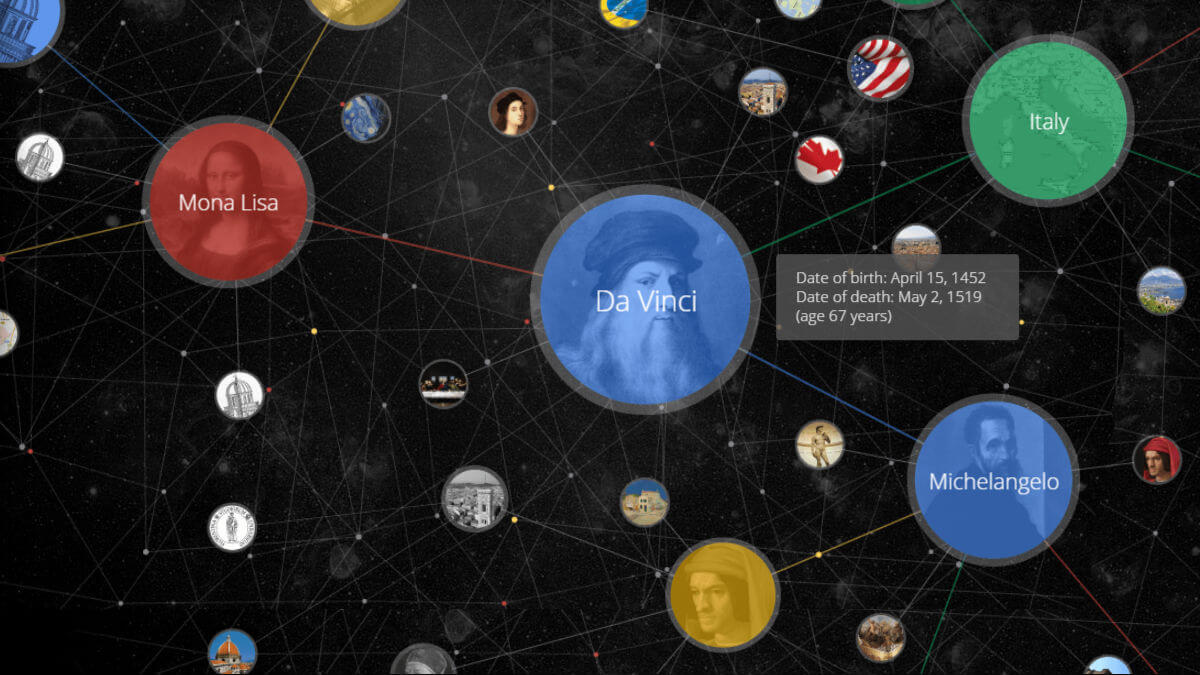
Per associare quindi le parole alle “cose reali“, Google sta costruendo il Grafo della Conoscenza, ovvero un grafo (insieme di elementi collegati tra di loro) che conterrà le connessioni (ovvero le modalità di interazione) tra cose reali.
Una persona, ad esempio Alessandro Manzoni, avrà una data di nascita, altezza e peso, un insieme di opere che ha realizzato nella sua vita, e sarà interconnesso con oggetti a lui strettamente correlati, come la città dove è nato, che rappresenta un altro nodo all’interno del Knowledge Graph. Ogni nodo ha quindi le proprie peculiarità ed è collegato ad altri nodi correlati.
Sapendo quindi che Milano è la città di nascita di Alessandro Manzoni, e che lo scrittore ha composto opere come “I promessi sposi” o “Il Conte di Carmagnola”, Google riuscirà a comprendere meglio quello che realmente vogliamo cercare e fornirà risultati più rilevanti e più precisi.
Non solo. La ricerca produrrà anche un pannello informativo (simile ad InfoBox che trovate su Wikipedia) che visualizzerà immediatamente tutto ciò che Google conosce sul nostro termine di ricerca; ovvero tutto ciò che è presente nel Knowledge Graph e che è interconnesso al nostro “nodo”.
3,5 miliardi di fatti già schedati
Google dichiara di aver già schedato 3,5 miliardi di “fatti” e circa 500 milioni di oggetti, entità… in pratica nomi. Nomi e fatti che possono essere riassunti in alcune categorie principali:
- Attori, registi, film
- Opere d’arte e musei
- Città e Paesi
- Isole, laghi e fari
- Album musicali e gruppi musicali
- Pianeti e veicoli spaziali
- Montagne russe e Grattacieli
- Squadre sportive
Ovviamente queste sono solo alcune delle categorie. Le relazioni tra i “nodi” sono molto importanti, perché consentono a Google di sapere chi è il regista che ha girato un film e quali sono gli attori, oppure quali veicoli spaziali hanno visitato un particolare pianeta.
Il pannello informativo
I fatti che verranno visualizzati nel “pannello informativo” inoltre, saranno diversi per ogni elemento, tenendo in considerazione i più visualizzati. Per esempio, come vedete nell’immagine a lato (al momento la funzionalità è attiva solo in lingua inglese, ma presto verrà estesa anche al nostro Paese), per entrambi i personaggi il pannello informativo visualizza la data di nascita e l’educazione scolastica. Gli altri “fatti” sono diversificati. Mentre per Matt Groening, creatore dei Simpons, sono presenti i genitori e i fratelli (per sottolineare l’assonanza con i nomi della famosa serie TV) e i premi vinti (awards), per Frank Lloyd Wright, famoso architetto statunitense, il pannello visualizza la data di morte, le mogli che ha avuto (spouse) e i figli (children).
Inoltre nella parte successiva, dove vengono elencate le opere più famose di questi due artisti, nel caso di Groening troviamo i suoi libri, mentre per Lloyd Wright troviamo le costruzioni. A concludere le ricche informazioni fornite dal pannello troviamo una selezione di altri nomi che Google mette in relazione a questi sulla base delle visualizzazioni precedenti, introducendo così una sorta di navigazione a catena attraverso una serie di argomenti correlati.
Cosa cambierà per chi ha un sito e vuole essere presente su google?
Questo nuovo modo di presentare i risultati affiancherà le normali ricerche di Google, quindi nessuno stravolgimento, di fatto, per chi vuole essere presente nell’indice. Partecipare ai risultati inclusi nei pannelli informativi, però, è altra cosa.
Al momento non ci sono ancora dati certi sulle modalità, ma sembra che aprire un account presso Freebase e contribuire possa aiutare. Personalmente non ci credo molto, e non spenderei troppo tempo su Freebase.
L’alternativa è contrassegnare parti delle pagine con tag schema di uso comune, come quelli di schema.org, consorzio formato da Google, Bing e Yahoo per l’adozione di un set comune di metadati per la descrizione dei contenuti di una pagina. Ma anche in questo caso, le probabilità che un crawler tenga conto delle informazioni e decida di includerle nel Grafo della Conoscenza, non sono note. Quindi personalmente sconsiglierei di usare i tag schema solo a questo scopo.
Quello che noi agenzie possiamo fare, è concentrarci sempre più sulla qualità dei contenuti delle nostre pagine, e sulla semantica dei tag che utilizziamo per costruire le pagine web. Una pagina ben costruita viene interpretata correttamente dai robot dei motori di ricerca, ed è più facile da mantenere ed eventualmente aggiornare con altri tag o metadati che divenissero necessari in futuro.
Attendiamo quindi con impazienza che anche nel Bel Paese arrivi questa nuova feature del gigante di Mountain View, e… “che la rivoluzione del semantic web abbia inizio!”
Il pannello InfoBox di Wikipedia

Il pannello informativo di google knowledge search
